Understanding Data Lakehouses and Data Meshes for Better Data Management
Written on
Chapter 1: Introduction to Data Storage Concepts
In the evolving landscape of data management, terms like Data Warehouse, Data Lake, Data Lakehouse, and Data Mesh have emerged. Understanding the distinctions and relationships between these concepts is crucial for organizations striving to become data-driven. This section will clarify these differences and illustrate how they can complement each other.
Section 1.1: The Data Lakehouse Explained
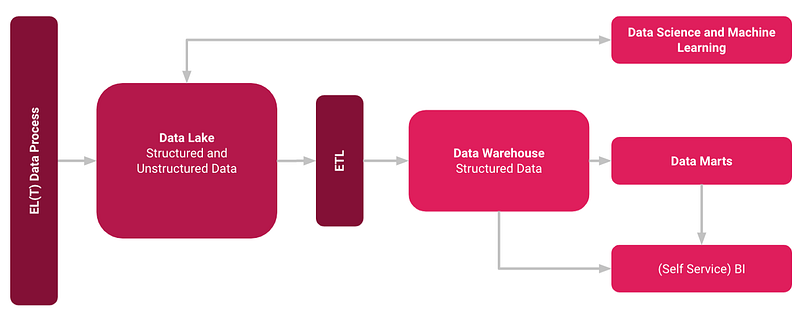
The Data Lakehouse serves as a hybrid model, merging the functionalities of both Data Lakes and Data Warehouses. It stores raw data within various Data Lakes, structured around specific business contexts, while also transferring processed and aggregated data into a Data Warehouse. This integration supports diverse applications such as Self-Service BI, Data Marts, and Machine Learning Services.

The Data Lakehouse is not merely an addition to existing systems but a unified approach that offers several benefits, including:
- Separation of data storage from processing, enhancing scalability.
- Utilization of open, standardized storage formats and interfaces.
- Capability to handle various data types, encompassing both structured and unstructured data.
- Support for multiple workloads, such as Data Science, Machine Learning, SQL, and Analytics.
- Continuous streaming capabilities that negate the need for isolated systems for real-time data applications.
- Reduced time-to-value compared to traditional Data Warehouses.
Section 1.2: Understanding the Data Mesh Approach
The concept of Data Mesh introduces a fresh organizational perspective, focusing less on technical solutions and more on structural principles. When establishing a Data Mesh, consider the following four core principles:
- Domain-oriented decentralized data ownership and architecture: A Data Mesh aims to empower individual business units, potentially leading to the development of one or more Data Lakehouses.
- Data as a product: The architecture of a Data Lakehouse facilitates the management of data as a product, enabling domain-specific teams to have full control over the data lifecycle.
- Self-service data infrastructure: Users can independently access data through self-service BI tools, while Data Scientists can utilize the same data for model development.
- Federated computational governance: Data should be managed and disseminated according to a defined role structure, with data catalogs serving as effective tools for organization.
Chapter 2: Integrating Data Lakehouse and Data Mesh
The relationship between Data Lakehouses and Data Meshes is not a rivalry but rather a complementary dynamic. The Data Lakehouse combines features of both Data Lakes and Data Warehouses, while the Data Mesh provides an organizational framework for data governance and distribution.
Video Description: In this presentation, James Serra discusses the integration of Data Lakehouse, Data Mesh, and Data Fabric, highlighting their roles in modern data management.
Video Description: This SQLBits 2022 session explores the interconnections between Data Mesh, Data Fabric, and Data Lakehouse, offering insights into their practical applications.
Summary
This overview aims to provide a foundational understanding of Data Lakehouses and Data Meshes and how they can work together to enhance data management strategies. For more in-depth knowledge, consider exploring further resources on Data Lakehouses and Data Meshes.
Sources and Further Readings
- Stefan Koch, Können Lakehouses einen Paradigmenwechsel anstossen? (2021)
- Michael Armbrust et al., Frequently Asked Questions About the Data Lakehouse (2021)
- Google, Build a data mesh on Google Cloud with Dataplex, now generally available (2022)