Transforming Your Complex URLs into Actionable Insights
Written on
Chapter 1: Understanding the Value of URLs
URLs are often seen as just metadata, but they actually hold a wealth of useful information that is frequently overlooked due to their unappealing appearance. While some URLs may seem daunting, they often contain data that can enhance analysis and significantly boost traffic and revenue for businesses.
One common example is the UTM parameters found in lengthy URLs. For digital marketers, these parameters provide critical insights into the sources driving traffic to their websites or landing pages. However, if you're not focused on digital marketing and are simply learning SQL, this may not resonate with you.
Even if you're not interested in traffic analytics, understanding how to parse URLs is important. URLs encapsulate some of the most intricate STRING-type data you'll encounter, and the functions used to extract meaningful information from them can be applied across various STRING operations in SQL.
Instead of drowning you in URL-specific functions, my goal is to present a few techniques that can be beneficial when handling longer strings, whether they be messages or even genetic sequences.
Note: Some functions discussed may be specific to BigQuery and might not be applicable across all SQL variants.
While public datasets in BigQuery include tables like HackerNews with vast amounts of standardized URLs, I prefer using URLs from my published Medium articles, which my personal ETL pipeline captures upon publication. You can read more about this process below.
Chapter 2: Requirements for URL Parsing
Before we dive into our first query, let's consider how to create a table that outlines URL attributes for a stakeholder. For a specific URL, we aim to generate new columns containing:
- My profile link
- The publication where the story appears
- The unique ID associated with each story
Here's an example of what a full URL looks like:

The good news is that extracting the hostname is relatively straightforward in BigQuery, thanks to its Net functions. The primary function we need is NET.HOST, which retrieves the hostname from a given URL.
SELECT url, NET.HOST(url) AS host_url
FROM (
SELECT url FROM ornate-reef-332816.medium.article_stats
WHERE DATE(dt_updated) = CURRENT_DATE()
)
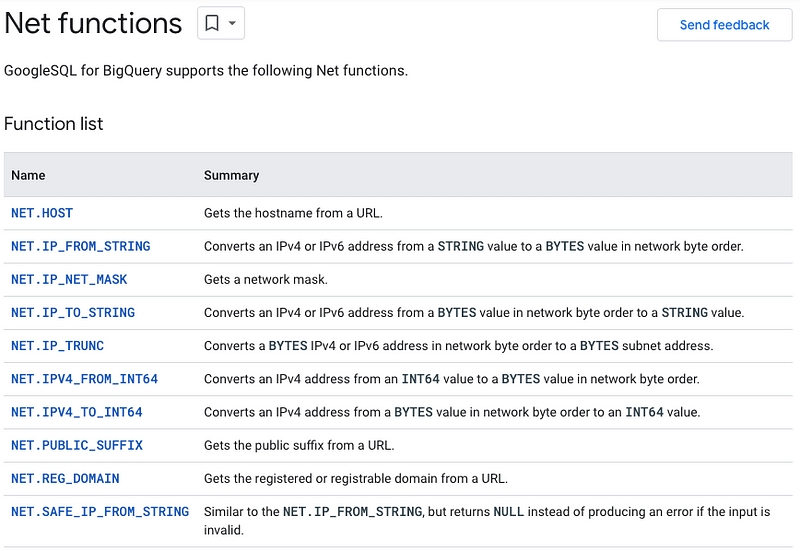
You could use the CONCAT() function, but I'll opt for the pipe operator:
SELECT url, host_url, host_url || "/" || "@zach-l-quinn" AS profile
FROM (
SELECT url, NET.HOST(url) AS host_url
FROM (
SELECT url FROM ornate-reef-332816.medium.article_stats
WHERE DATE(dt_updated) = CURRENT_DATE()
)
)
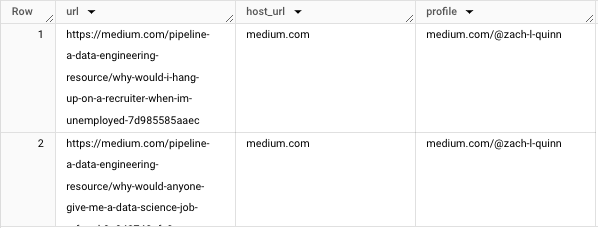
For the remaining requirements, we'll utilize the SPLIT() function. To extract the publication name, we'll split the URL string at a designated character. For this, we'll use the preceding "/." As there are multiple slashes, we'll specify that we want the value after the slash at index position 3.
SELECT url, host_url, host_url || "/" || "@zach-l-quinn" AS profile, publication
FROM (
SELECT url, NET.HOST(url) AS host_url, SPLIT(url, "/")[OFFSET(3)] AS publication
FROM (
SELECT url FROM ornate-reef-332816.medium.article_stats
WHERE DATE(dt_updated) = CURRENT_DATE()
)
)
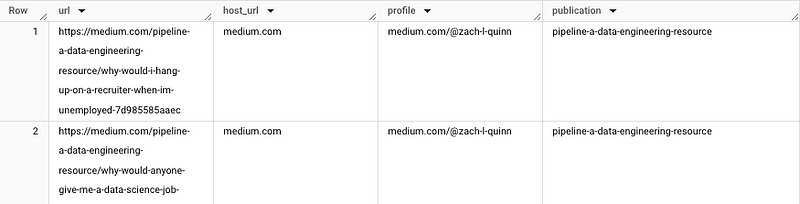
Finally, we need to extract the ID, which is the alphanumeric string at the end of the URL. We will first SPLIT() the URL on the last "/" and then select the appropriate segment using OFFSET.
SELECT url, host_url, host_url || "/" || "@zach-l-quinn" AS profile, publication, SPLIT(split_url, "-")[SAFE_OFFSET(11)] AS id
FROM (
SELECT url, NET.HOST(url) AS host_url, SPLIT(url, "/")[OFFSET(3)] AS publication, SPLIT(url, "/")[SAFE_OFFSET(4)] AS split_url
FROM (
SELECT url FROM ornate-reef-332816.medium.article_stats
WHERE DATE(dt_updated) = CURRENT_DATE()
)
)
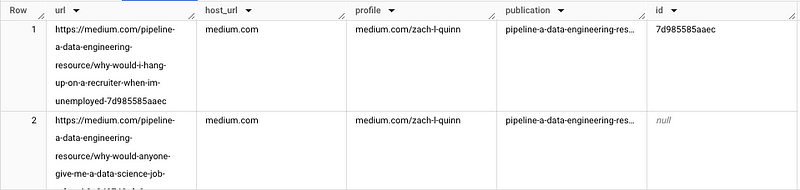
While the ID extraction works well for the first row, the second row may present issues. Precision is key, as the variable length of story titles can lead to an inconsistent number of dashes.
As a workaround, I can filter for IDs that already exist in my base table:
SELECT *
FROM (
SELECT url, host_url, host_url || "/" || "@zach-l-quinn" AS profile, publication, SPLIT(split_url, "-")[SAFE_OFFSET(11)] AS id
FROM (
SELECT url, NET.HOST(url) AS host_url, SPLIT(url, "/")[OFFSET(3)] AS publication, SPLIT(url, "/")[SAFE_OFFSET(4)] AS split_url
FROM (
SELECT url FROM ornate-reef-332816.medium.article_stats
WHERE DATE(dt_updated) = CURRENT_DATE()
)
)
)
WHERE id IN (SELECT id FROM ornate-reef-332816.medium.v_story_stats)
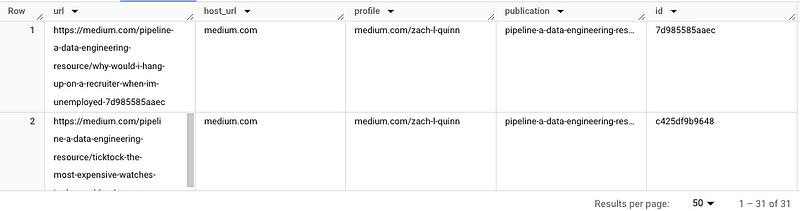
This approach reduces my row count from over 200 to just 31, which is acceptable given that I’m the stakeholder. Since I already store these ID values, I'm not concerned about losing critical data.
Recently, I found myself needing to manipulate and extract values from URLs in SQL again. After a year away from similar tasks, I wanted to refresh my skills in URL extraction and STRING manipulation.
This exercise isn't merely about SPLIT() functions; URLs are a fascinating subset of STRING data that can contain valuable, business-related insights. Now, you can reveal these insights for your stakeholders or yourself.