Understanding the Limitations of LLMs in Coding Tasks
Written on
Chapter 1: Introduction to LLMs for Coding
Following the release of my initial piece, “Why LLMs are Not Good for Coding,” I encountered numerous responses on social media that caught me off guard. Comments like:
“I use ChatGPT for coding and it works flawlessly.”
“You are mistaken. Large Language Models serve as valuable coding aids.”
These reactions were unexpected because the aim of this series is not to dissuade anyone from utilizing LLMs for coding but rather to pinpoint areas for enhancement to make these models more efficient coding assistants.
While tools like ChatGPT can prove beneficial in certain situations, they frequently generate code that, while syntactically correct, may be ineffective or even erroneous in its functionality. In the previous article, we explored how elements such as tokenization, context window complexities, and the training process itself can affect these models' performance in coding tasks.
Section 1.1: Training Processes for Coding Models
In this article, we will delve into the specific training methodologies that these models undergo to assist with coding tasks. Additionally, we will examine a significant challenge that prevents LLMs from being immediately adept at coding: their struggle to keep pace with the latest libraries and code functionalities.
LLM-driven coding tools are now commonplace, with GitHub Copilot being one of the most recognized options, offering code suggestions and chat support directly within development environments. According to the developers, “GitHub Copilot generates suggestions based on probabilistic reasoning.” A deeper dive into their documentation reveals essential details about the product's functionality:

This means that wherever the cursor is placed, a suggestion will follow.
However, it's crucial to note that general LLMs are designed to predict the next token based solely on a sequence of preceding tokens, which means that only the lines immediately preceding the cursor are used for inference (left-to-right generation). There are bi-directional models that utilize both left and right contexts for predictions; however, in practice, unidirectional models like ChatGPT employ workarounds for efficient code usage.
A common method to prepare a base LLM for coding involves adaptive fine-tuning on code datasets, similar to how models are specialized on specific topics in Natural Language. Yujia Li (DeepMind) illustrated this process in the article “Competition-Level Code Generation with AlphaCode”:
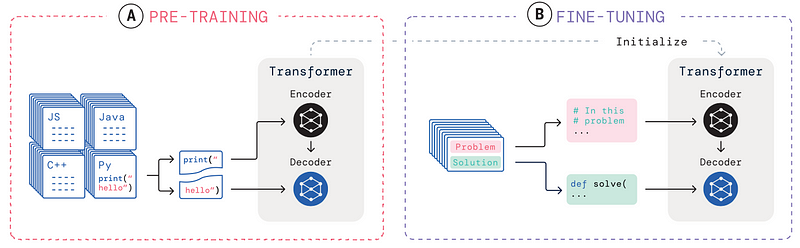
As depicted in section (A) of the diagram, general coding LLMs are initialized with a base model that has been pre-trained on natural language, followed by training on code repositories. For instance, given a context such as print(", the model learns to predict the completion hello using left-to-right generation. Subsequently, models undergo fine-tuning utilizing a range of coding problems and their solutions, as shown in (B). Thus, when faced with a coding challenge, the model is trained to generate the correct solution.
By pre-training LLMs on code datasets, these models become familiar with the specific patterns, styles, and structures found in programming languages. Furthermore, the fine-tuning dataset should encompass various coding tasks, including code completion and infilling, to enhance the model's ability to predict suitable code snippets based on preceding context. Post-training, another approach to ensure the model captures the correct context is to include it as part of the prompt during inference.
For example, in the context of code infilling, the prompt can incorporate surrounding code as context, effectively reshaping the task to align with the model’s unidirectional nature.
Section 1.2: Challenges of LLMs as Coding Assistants
In the first article of this series, we examined various limitations faced by LLMs when producing code, but we overlooked one critical issue: the challenge of staying current with the latest packages and functionalities.
In the realm of software development, staying updated is vital for crafting effective and secure code. However, this is particularly challenging for LLMs due to two main factors:
- Static Knowledge Base: Like any LLM, GitHub Copilot is trained on a fixed dataset—code and documentation—gathered at a specific time. As a result, it might not be aware of new functions, deprecated features, or security updates released after its last training cycle.
- Version Specificity: Software development is heavily dependent on precise versions of libraries and frameworks. Since LLMs are not continually updated, they risk offering outdated code snippets, resulting in compatibility problems or the use of deprecated methods. APIs can change frequently, and new features may be introduced or removed. LLMs trained on older data may not recognize new security vulnerabilities, which can compromise code integrity.
Moreover, managing dependencies in modern software development is intricate, and LLMs may not provide the best guidance if they lack the latest compatibility and version information.
Chapter 2: Potential Solutions
Integrated Development Environments (IDEs) and other coding tools could incorporate real-time updates to access the latest documentation or library versions, akin to how the Bing browsing feature enhances ChatGPT-4's knowledge base.
To my knowledge, GitHub Copilot's chat feature already possesses browsing capabilities. Nevertheless, as highlighted earlier, LLMs primarily depend on their pre-trained models for generating outputs, and GitHub Copilot itself cautions users about this in its documentation.
“GitHub Copilot offers suggestions from a model built by OpenAI utilizing billions of lines of open-source code. Consequently, the training dataset may include insecure coding patterns, bugs, or references to outdated APIs or idioms. As a result, suggestions generated by GitHub Copilot may also reflect these undesirable patterns.”
When employing LLMs as coding assistants, it's crucial to recognize that their ability to dynamically consult external databases for software updates and documentation may be limited.
Final Thoughts
While Large Language Models can serve as helpful partners in generating foundational code and assisting with syntax and basic concepts, it's important to be mindful of their limitations and avoid over-reliance on these tools. Each coding endeavor may necessitate highly tailored solutions that align with specific business rules or user needs—nuances that LLMs, trained on general patterns, often struggle to capture.
However, we can implement Prompt Engineering techniques specifically designed for coding to steer the LLM toward our desired outcomes. If you're interested, you can explore this further in the following article:
Prompt Engineering for Coding Tasks
Enhancing Code Generation with LLMs via Prompt Engineering
towardsdatascience.com
The first video titled "90% Percent Of My Code Is Generated By LLM's" discusses how LLMs can effectively assist in coding, providing insight into their practical applications.
The second video titled “What's wrong with LLMs and what we should be building instead” features Tom Dietterich discussing the limitations of LLMs and suggesting alternative approaches for development.
In conclusion, writing functional code is one aspect; optimizing it for performance is another. It's essential to acknowledge that LLMs may not always produce the most efficient algorithms or tailor code for specific hardware or software environments. Additionally, security considerations should always be a priority when executing AI-generated code.
Ultimately, Large Language Models rely on maximum likelihood estimations, while effective software development demands performance-aware code generation strategies. Thank you for reading! I hope this article aids you in utilizing LLMs for coding effectively.
Consider subscribing to my Newsletter to stay updated on new content, especially if you're interested in articles focused on Large Language Models and ChatGPT:
- Why LLMs are Not Good for Coding
- Challenges of Using LLMs for Coding
towardsdatascience.com
- ChatGPT Moderation API: Input/Output Control
- Using the OpenAI’s Moderation Endpoint for Responsible AI
towardsdatascience.com
- Custom Memory for ChatGPT API
- A Gentle Introduction to LangChain Memory Types
towardsdatascience.com